Modelador de Dados
| Site: | 4Insights |
| Curso: | 4Insights |
| Livro: | Modelador de Dados |
| Impresso por: | Usuário visitante |
| Data: | Monday, 27 Oct 2025, 07:39 |
Sumário
- 1. Acessando o Modelador de Dados
- 2. Configurando Ambientes
- 3. Fluxo e Etapas
- 4. Primeiros Passos
- 5. Módulos
- 6. Snowflake e Star Schema
- 7. Dimensão
- 8. Tabela de Upload
- 9. Atributos
- 10. Lookups da dimensão
- 11. Definição de hierarquias
- 12. Dimensão de Tempo
- 13. Fato
- 14. Importar e Exportar Módulos
- 15. Verificando Pendências
- 16. Aprovando as Alterações
- 17. Desfazendo as Alterações
- 18. Visualizar Histórico
- 19. Obter versão especifica
- 20. Migração de Módulos
- 21. Geração de Diagramas
- 22. Propriedades do Modelo
- 23. Hierarquia de Versões
- 24. Configurações Avançadas
1. Acessando o Modelador de Dados

O Modelador de Dados é uma ferramenta visual para modelagem. É nela onde se constrói o modelo multidimensional. Ao acessar o 4Insights, o menu pode ser facilmente encontrado na barra como ‘Modelador de Dados’.
O 4Insights é uma solução de múltiplas clientes e múltiplos ambientes. Consulte o módulo Cliente no menu Administração deste treinamento para obter detalhes sobre como cadastrar novos Clientes.
2. Configurando Ambientes
Criar um ambiente é uma maneira de separar as responsabilidades, isolando totalmente os dados que serão carregados, o repositório de arquivos e parâmetros.
Para criar um ambiente, selecione o botão “Ambientes” localizado no menu de ferramentas do Modelador de Dados e começar
a configuração em um formulário.

Informações do Ambiente
Em “Informações de Ambiente” é possível selecionar um ambiente de origem ou iniciar um ambiente do zero. Ao determinar um ambiente de origem, a ferramenta cria um fluxo no qual é permitido migrar o modelo de um ambiente para outro, como por exemplo, migrar o ambiente de desenvolvimento para o ambiente de homologação. Além disso, existe uma trava de edição para o ambiente, e garante que a equipe siga o fluxo determinado na configuração. Ou seja, caso o botão "Permitir Edição" de homologação esteja desligado, o usuário será obrigado a realizar as alterações do modelo no ambiente de desenvolvimento e migrar para o ambiente de homologação sempre que necessário sem a possibilidade de modificar o modelo diretamente no ambiente de homologação. Porém, se o botão permitir edição esteja ligado, será possível modificar diretamente no ambiente de homologação e devolver para o ambiente de desenvolvimento, contudo esta é uma prática não recomendada.

Parâmetros Gerais
O 4Insights possui um mecanismo que que valida as chaves primárias e estrangeiras, os campos de valores pré-definidos (valores de checagem) e outras consistências que são definidas durante a fase de modelagem. Quando os dados são criticados ou rejeitados por este mecanismo, eles são armazenados em tabelas separadas no banco de dados. Por exemplo, quando você determina uma tabela de upload chamada "in_vendas", o 4Insights cria uma tabela chamada "r_in_vendas" e, se algum dado for rejeitado, será armazenado nesta tabela.
O parâmetro "quantidade de dias de rejeições" é o parâmetro que controla a quantidade de dias que as informações rejeitadas serão guardadas, após expirada esta quantidade de dias, o sistema elimina estes dados rejeitados.

Configuração da Carga
O parâmetro "URL do 4Insights" é o parâmetro que configura o servidor onde módulo do 4Insights Engine está sendo executando, ou seja, o endereço por onde será acessado.

Tipo de Engine
Nesta opção, você deve indicar se este ambiente irá trabalhar com Banco de Dados ou Hadoop.

Para configuração "Banco de Dados" acesse o módulo Banco de Dados
Para configuração "Hadoop" acesse o módulo de configuração Hadoop
Módulo de Tempo
O módulo tempo é uma dimensão padrão do 4Insights e comum para todos, pois consideramos que toda informação precisa ser analisada no decorrer do tempo, e por este motivo é necessário incluir este módulo no algorítimo do 4Insights e tanto a carga quanto o desenho não precisam ser desenvolvidos. Os parâmetros deste módulo são dois: o primeiro é "início da carga" que determina o primeiro dia em que as informações de tempo serão armazenadas no banco de dados. O segundo parâmetro determina a quantidade de dias que as informações serão carregadas à partir da data do processo (Data atual). Quando o processo de carga for executado, a ferramenta irá incluir as informações deste modelo no banco de dados sem a necessidade de intervenção de uma programação.

Parâmetros de Flat Files
O 4Insights Plug-in (ETL) converte as informações para um padrão de Flat File e transporta estes arquivos para os repositórios, por este motivo é necessário informar em qual repositório estes arquivos deverão ser armazenados.
O parâmetro "Tipo de repositório" determina se o repositório é do tipo Storage (pasta do sistema operacional), AWS S3 (repositório de arquivos da Amazon) ou Azure Blob (repositório de arquivos da Microsoft). Portanto, os parâmetros são diferentes conforme o seu tipo.
Para o tipo "Storage": o "Local do repositório" é a pasta na qual os arquivos serão armazenados, por exemplo "/home/dwupload/DATA_FILE"; "Nome do host" é o servidor onde será armazenado; "usuário" e "senha" são as credenciais da máquina. A conexão que será utilizada quando o tipo for Storage é SFTP e o usuário precisa ter privilégios suficientes para ler e escrever na pasta informada.

Enquanto isso, para tipo AWS S3, "Access Key", "Secret Key", "Region Name", "Bucket Name" e "Local Repository" são os parâmetros de configuração do
serviço S3 da Amazon. Para maiores detalhes,
clique aqui.

Para configuração do Azure Blob, será necessário informar o nome da conta, chave da conta, nome do contêiner e o local do repositório.
Para mais informações, Clique aqui

Para configurar os parâmetros de log, será necessário indicar apenas o local do repositório.

Enquanto que para a configuração dos parâmetros de chave-valor, é necessário especificar duas opções, exemplo:
- Chave - usada para identificar qual informação está no campo "Valor".
- Valor - pode ser o nome de uma tabela.

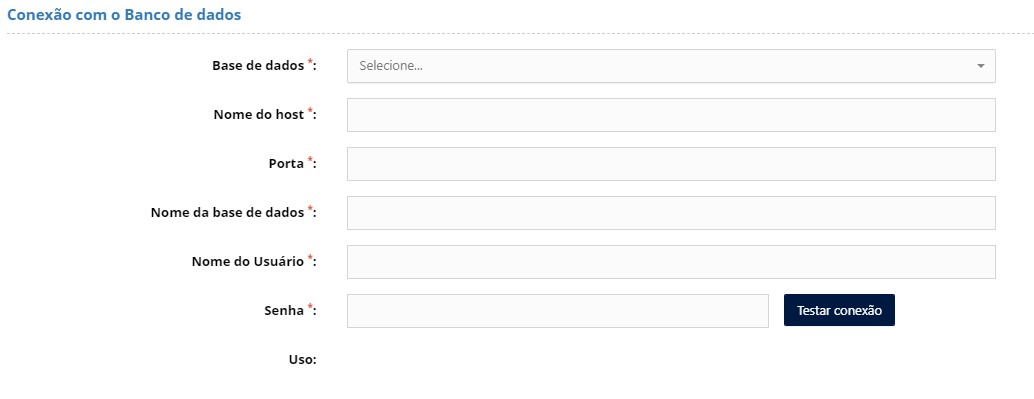
2.1. Banco de Dados
Os parâmetros abaixo são destinados a parametrização do banco de dados no qual as informações serão armazenadas (Repositório Analítico).
No parâmetro "Base de Dados" é possível escolher o tipo de banco de dados, tal como PostgreSQL, Amazon AWS - Redshift, Snowflake, GreenPlum, DB2Blu, MariaDB, SQL Server e Azure SQL Data Warehouse.
"Nome do Host" é o nome do servidor ou IP e porta é onde o banco de dados selecionado está instalado;
"Nome da base de dados" é o nome dado na criação da base dentro do servidor;
"Nome do Schema" é disponível somente para alguns tipos de bancos de dados. Com esta opção, além do nome do banco de dados, é necessário informar o "schema".
Por fim, é necessário informar "Nome do Usuário" e "Senha" para acesso do banco de dados. Observe que este usuário deve possuir privilégios de leitura e escrita no banco de dados, pois é este usuário que irá criar e manter as tabelas neste repositório.
2.2. Hadoop
Na configuração através do Hadoop, temos duas opções:
-
Hortonworks - Para mais informações clique aqui!
- AWS EMR - Para mais informações clique aqui!
Configurando Hortonworks
Para configurar seu ambiente usando o Hortonworks, preencha as informações conforme abaixo:

Conexão com o Hive - preencha o "Nome do host", "Porta", "Nome da base de dados, "Nome do usuário" e "Senha".
Conexão com o Presto - preencha o "Nome do Host", "Porta", "Database do Hive", "Nome do Usuário" e "Senha".
Configurando AWS EMR
Para configurar seu ambiente usando o AWS EMR, preencha as informações conforme abaixo:

Nas configurações do AWS EMR temos que indicar as configurações de Conexão com o Hive e Conexão com o Presto, assim como na configuração do Hortonworks, porém também é preciso indicar as informações de cluster, são elas:
- Cluster Name - Nome do cluster do EMR
- Access Key - chave de acesso
- Secret Key - chave secreta
- Region Name - Nome da região, exemplo us-east-1
3. Fluxo e Etapas
Fluxo e Etapas
Abaixo temos uma ilustração do fluxo padrão das informações utilizado na plataforma 4Insights:

1ª Etapa: Desenhar o modelo de dados no Modelador de Dados, no qual os objetos* são definidos. Eles são definidos na primeira etapa. Alguns objetos são necessários para o funcionamento correto, dentre eles:
a) Upload -Objeto de partida para definição do modelo de dados. Este objeto é obrigatório e os atributos e os campos das tabelas são definidos nele. Este objeto serve tanto como base para os demais objetos que serão construídos no modelo de dados, como também de base de integração para o plug-ins. Normalmente denominamos conceitualmente esta camada em BI, como Staging Area. Neste momento as informações já estão sendo convertidas em tabelas e por este motivo definimos neste objeto algumas regras, como chave primária e chave de atualização (que iremos detalhar neste treinamento). Este objeto também tem como objetivo criar uma camada denominada Work e nela será realizado o processo de tratamento de dados.
b) Tabelas - Neste objeto iremos definir as tabelas de Fatos/Dimensões ou Lookup. Os objetos e tabelas são construídos através do objeto Upload, utilizando o mesmo conceito de arrastar e soltar.
Alguns objetos ainda são criados pela ferramenta.
- O primeiro é a camada de rejeição dos dados. Para cada tabela de Upload será criada uma tabela de Reject (rejeição), ou seja, uma camada de tratamento de dados para os dados que não passarem pela validação definida no modelo de dados.
- O outro é a camada de processamento (tabelas temporárias). Estas tabelas são criadas no momento do processamento e eliminadas ao término.
O 4Insights possui um padrão de nomenclatura próprio, que tem como objetivo facilitar a utilização dos objetos e interpretação de cada camada.

Mas caso você tenha a necessidade de ter uma nomenclatura customizada para os objetos, o 4insights também possibilita sua modificação através da tela de "Propriedades" que é encontrada no menu do canto esquerdo na barra de ferramentas do modelador de dados.
A partir das tabelas de fatos e dimensões, outras tabelas serão criadas. São elas as tabelas 'Agregadas' (resumo de uma tabela de fatos), 'Hierarquia entre Lookups' (que são tabelas para se desenhar os modelos Snow Flake/Star Schema/Híbrido). No exemplo abaixo, temos um modelo de dados no qual as caixas laranjas representam as dimensões e as caixas azuis representam as informações de fatos.

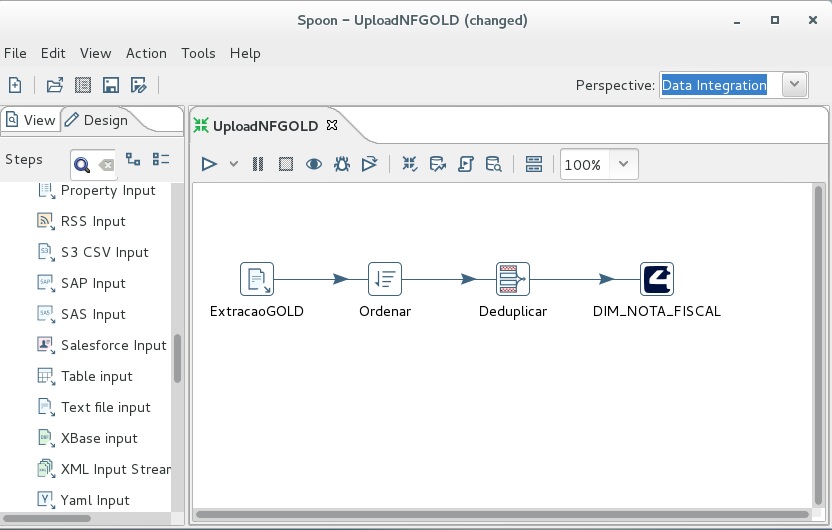
2ª Etapa: Exemplificando a construção de processos de extração das informações e entregá-las para o plug-in do 4insights.
Nesta etapa exemplificaremos utilizando uma ferramenta open source chamada PDI (Pentaho Data Integration). No exemplo abaixo, a ferramenta está conectada em um banco de dados Oracle ordenando os dados, removendo as duplicações e entregando os dados para o plug-in.
Esta ferramenta é bem completa e irá facilitar todo o processo de extração de dados, bem como simplificar e acelerar esta etapa do processo. Para saber mais clique aqui.
* São objetos "Tabela de Upload", "Tabela Fatos/Dimensões".
4. Primeiros Passos
Após a configuração do ambiente estamos prontos para começar a modelar, neste tópico iremos detalhar como será as primeiras interações com a ferramenta de modelagem. Primeiramente toda a modelagem desenvolvida é feita de forma versionada, sendo assim quando um usuário está editando outro usuário não pode editar, o 4insights mantem todas as versões do modelo que podem ser recuperadas em qualquer momento. Para darmos inicio aos primeiros passos, com a tela de modelagem aberta, selecione na caixa de seleção no canto superior o Ambiente que foi criado anteriormente. ao selecionar esse ambiente será exibida a pagina em branco, conforme a imagem abaixo:
Conforme mencionamos acima, toda a modelagem é feita de forma versionada, sendo assim para que será possível a edição clique no menu do canto esquerdo "Habilitar Edição".

Ao clicar nesse menu o modelo estará bloqueado para o seu usuário até que você efetue a aprovação da sua versão do modelo ou descarte as alterações, você pode identificar que a edição está para o seu usuário pela mensagem exibida no canto superior da tela "Você está editando essa tela - Versão: 1", note que ao criar a primeira versão o 4insights já criou uma caixa chamada "Módulo Dimensão de Tempo", essa dimensão será detalha nos próximos tópicos.

Neste momento já é possível criar a modelagem, que será detalhada de forma mais abrangente nos próximos tópicos.
5. Módulos
Módulos
Módulo é um agrupador conceitual das informações que estão sendo tratadas, ou seja, agrupa informações que futuramente serão tabelas. Existem dois tipos de módulos: dimensão e fato. Ao clicar com o botão direito do mouse sobre o Painel de Modelagem, a ferramenta disponibiliza a opção "Adicionar Módulo", conforme abaixo:

A janela de inclusão de módulo permite selecionar qual o tipo de módulo será criado (Dimensão ou Fato).

As duas guardam objetos, mas atuam de formas diferentes. A dimensão trata de informações que dão sentido a alguma medida e que possuem atributos e níveis diferentes dentro desta dimensão. Por exemplo: "Dimensão Cliente", "Dimensão Tempo", "Dimensão Loja", "Dimensão Produto/Material".
A Dimensão Tempo é composta por vários atributos, como: data, dia, dia da semana, mês, bimestre, trimestre, semestre e ano. Os atributos de uma dimensão agrupam as informações que podem ser medidas, como por exemplo, o "Atributo Mês", que agrupa as vendas. Já o módulo Fato é composto por informações que podem ser calculadas, somadas e computadas, neste exemplo, as vendas. É neste módulo onde estarão as informações agregáveis, com dados que podem ser mensurados e analisados.
Os modelos "Multidimensionais/Dimensionais" são compostos por dois tipos e destintos de informações:
- Informações que serão medidas, são compostas por tabelas de fatos. Os fatos são repositórios nos quais armazenamos informações métricas (campos em tabelas que serão utilizados para medir, calcular, somar...). Por exemplo: Uma tabela de fatos de Vendas possui: "Valor da venda com impostos", "Valor dos custos das vendas", "Valor dos impostos". Nestas tabelas de fatos, relacionamos as dimensões pelas quais podemos medir. Por Exemplo: O "Valor da venda com impostos", está associado a um dia que ela ocorreu, a uma loja, a um produto que foi vendido, a um tipo de movimento (Venda ou Devolução da Venda).
- Atributos de análises: São as informações pelas quais podemos analisar a informação que devem ser medidas. Por Exemplo: Loja, Região da Loja, Estado que se localiza a loja, produto, categoria do produto, classe do produto. A dimensão é organização lógica dos atributos de análise. Por exemplo: "Dimensão Estrutura de Loja" é a composição dos atributos da loja, que neste exemplo são: Loja, Região da Loja, Estado que se localiza a loja".
O módulo de dimensão conta com dois tipos de objeto: "Upload"; "Lookup". Já o módulo de fato conta com diversos tipos de objetos: "Upload"; "Tabela de Fato"; "Agregado"; "Fotografia".
As tabelas de "Upload" e "Tabela de Fato" têm as mesmas funções que na dimensão. Já a "fotografia" é referente a um dado não agregável. Por Exemplo, o estoque não pode ser somado no decorrer do tempo, pois, se somarmos o estoque do dia 1 com o estoque do dia 2, teremos o estoque dobrado. Portanto, para este tipo de informação, tiramos uma fotografia do estoque. Já o "agregado" é composto por dados que podem ser somados no decorrer do tempo, como por exemplo, as vendas que, ao somar o dia 1 mais o dia 2, reflete uma informação coerente.
5.1. Propriedades
Ao criar um módulo o 4insights possibilita uma serie de propriedades que são diferentes entre Dimensão e Fato, neste tópico será ilustrado de forma detalhada, começando pelo módulo de Dimensão.
Propriedades de um Módulo de Dimensão
O módulo de dimensão ao ser criado pode ser habilitado as propriedades "Modulo de Tempo", "Habilitar versionamento", "Habilitar inserção automática de chaves estrageiras quando houver rejeição", "Habilitar Script SQL de pré-execução" e "Habilitar Script SQL de pós-execução".

Propriedade "Modulo de Tempo"
Ao habilitar essa propriedade você está dizendo ao 4insights que esse módulo irá conter informação de tempo, tais como Data, Semana, Mês, Semestre etc. Por padrão o 4insights já disponibiliza um módulo de tempo que é alimentada de forma automática, descartando a necessidade da construção de um processo de extração, esse módulo será detalhado nos próximos tópicos.
Propriedade "Habilitar versionamento (Slowly Changing Dimension)"
Ao habilitar essa propriedade o 4insights irá considerar que essa dimensão será versionada, de forma que na entrada dos dados seja mantido o histórico dos registros existentes com a mesma chave, para garantir esse controle o 4insights irá incluir as seguintes colunas na tabela "Lookup":
- Surrugate: Essa coluna irá conter um sequencial que será gerado na inserção do registro garantindo a unicidade do mesmo.
- Data de Inicio da Vigência: Essa coluna irá conter a data em que o registro inicia sua validade.
- Data de Fim da Vigência: Essa coluna irá conter a data em que o registro encerra sua validade, sendo o valor atualizado quando uma nova versão do registro for processada.
Obs.: O 4insights somente irá versionar registros que são carregados de forma lenta, ou seja, não sendo possível o versionamento do mesmo registro na mesma carga.
Propriedade "Habilitar inserção automática de chaves estrangeiras quando houver rejeição"
Por padrão o 4insights ao processar os dados de uma dimensão que tem relacionamento com outra (uma Foreign Key) é realizado uma validação lógica para garantir que o registro exista na tabela relacionada, e caso o registro não exista, o 4insights irá rejeitar esse registro e inseri-lo na tabela de rejeição (Reject), mas ao habilitar essa propriedade o processo de carga se comporta de maneira diferente, sendo que ao invés de rejeitar o registro ele é inserido na tabela relacionada com os valores padrão das colunas que são definidos na criação do atributo. Sendo assim o registro irá passar por essa validação e ir para a tabela de negócio.
Propriedade "Habilitar Script SQL de pré-execução"
Com essa propriedade habilitada o usuário pode escrever um Script SQL que será executado antes do processo de carga começar, esse Script pode conter varias instruções, desde que sejam separadas por ponto e virgula (;), nessa área você pode utilizar os parâmetros criados na configuração do ambiente usando a seguinte syntaxe ${<nome da variável>}.
Ex.: Insert into temp_foo as select * from ${schema_name}.foo
Propriedade "Habilitar Script SQL de pós-execução"
Com essa propriedade habilitada o usuário pode escrever um Script SQL que será executado depois que todo o processo de carga deste módulo, esse Script pode conter varias instruções, desde que sejam separadas por ponto e virgula (;), nessa área você pode utilizar os parâmetros criados na configuração do ambiente usando a seguinte syntaxe ${<nome da variável>}.Ex.: Insert into temp_foo as select * from ${schema_name}.foo
Propriedades de um Módulo de Fato
O módulo de fato ao ser criado pode ser habilitado as propriedades "Habilitar Script SQL de pré-execução" e "Habilitar Script SQL de pós-execução" e tem o mesmo comportamento das mesmas propriedades do módulo de dimensão.

6. Snowflake e Star Schema
Snowflake, Star Schema ou Hybrid Schema?
No BI existem esquemas lógicos para a modelagem dos dados. Dois esquemas se destacam como os mais eficazes e utilizados: ‘Snowflake’ e o ‘Star Schema’. Os dois esquemas contam com benefícios e o que recomendamos é um esquema híbrido, que utiliza características tanto de snowflake quanto de star schema.
Snowflake schema
Snowflake tem esse nome porque se parece visualmente com um floco de neve, devido ao relacionamento entre os dados. Aqui, várias dimensões (lookups) se relacionam com uma tabela de fato, de modo que os dados ficam em uma cascata (hierarquia) e mais distantes da tabela de fato. O dado passa por todos os outros objetos até atingir o destino final: a análise. Este esquema tem uma ótima governança de dados e não apresenta redundâncias.Entretanto, se apresenta mais lento e mais complexo, pois quando necessitamos analisar o nível menos granular é necessário relacionar todas as tabelas durante a análise até atingir a análise desejada.
Star schema
Star Schema é o modelo mais simples. Ele tem esse nome devido ao formato de estrela que o modelo obtém após construído. O esquema consiste em diversas dimensões ligadas a uma tabela de fato. As dimensões armazenam eventos, enquanto a tabela de fato guarda fatos ocorridos e chaves para características referentes, ao contrário do Snowflake. Desta forma, a performance aumenta significativamente devido a menor quantidade de chaves externas e a menor necessidade de junções durante a análise. Entretanto, os dados são muito redundantes e uma simples alteração pode gerar necessidade de várias outras alterações ou manutenções no banco de dados.
Esquema híbrido
Para melhor desempenho e governança de dados, o esquema híbrido é um esquema que une Snowflake e Star Schema para melhor governança de dados e performance, assim como para tornar o esquema mais normalizado e com menos redundâncias. Este esquema também permite uma maior consistência dos dados e facilidade de manutenção.
7. Dimensão

A construção de modelos é um dos principais fatores para tornar a 4Insights a solução de BI mais rápida do mercado. Desenhar os modelos dispensa escrever linhas e linhas de código, pois requer ao usuário somente conhecimento da lógica do negócio.
Para criar um módulo de dimensão, basta clicar com o botão direito em um espaço vazio, adicionar um módulo, selecionar "dimensão" e, em seguida, nomeá-lo. O "Nome Interno" é o nome físico (1) e o campo "Nome" é referente um nome lógico (2). O campo "Comentário" é muito importante para a organização dos dados: descrever os módulos, as tabelas e até os atributos é importante para que toda a estrutura dos dados esteja organizada. Também podemos utilizar o campo de descrição para informar detalhes relevantes dos dados: sua origem, como se obtém, quais são suas regras e tudo o que precisa estar documentado.
É importante lembrar que o 4Insights possui uma ferramenta que exporta todas as informações. Tanto no modelo PDF, como modelo JSON. Isso será importante para a geração da documentação do seu projeto.
Com a dimensão criada, é possível adicionar tabelas, e o processo é o mesmo dos apresentados anteriormente: clicar com o botão direito e adicionar elementos. Podem ser eles: Upload e Lookup, que já foram explicados no tópico anterior. O Fluxo abaixo descreve a ordem de como a dimensão deve ser criada:

8. Tabela de Upload
Para inciar o processo de elaboração da dimensão de fatos, abra o módulo e clique com o botão direito do mouse sobre qualquer parte
da área de trabalho do
modelador de dados e selecione "Adicionar elemento" e selecionar o tipo "Upload". Agora é possível adicionar atributos, associar atributos de outros módulos à este elemento
Upload e importar atributos, esse assunto será detalhado melhor no próximo tópico, como mostra a imagem abaixo. Para entender o motivo, verifique tópico
Fluxo e Etapas. Para isto, crie a tabela de Upload, clicando com o botão direito do mouse e selecione a opção
"Adicionar Elemento".

Selecione a opção "Upload" na caixa de seleção "Tipo", informe um nome funcional (Name) e um nome físico (Internal Name) para a tabela de upload, após definir essas informações, agora você deve escolher o tipo de entrada (Flat File ou Staging Area)

Flat File
Ao selecionar essa opção o 4insights irá utilizar um arquivo no formado CSV para realizar a carga dos dados para da tabela de Upload, para isso é necessário utilizar o plug-in para as ferramentas de ETL pois ele se encarregará de criar esse arquivo e transferir para o repositório correto, esse repositório foi definido na seção "Parâmetros do Flat File" que foi configurado na criação de um novo ambiente, e ao iniciar o processo de carga, o 4insights vai identificar os arquivos à serem processados e iniciará a carga deles para a tabela de Upload
Obs.: Cara banco de dados possui uma forma especifica de carregamento de arquivos para o banco de dados, mas o 4insights se encarregará de usar a melhor estrategia para a carga dos arquivos.
Staging Area
Ao selecionar essa opção o 4insights cria uma tabela com a mesma estrutura da tabela de Upload, que será utilizada para que ferramentas externas possam fazer carga de dados para essa tabela, como por exemplo uma fila de eventos de um processo de "Near Real Time", e quando o módulo é executado os dados dessa tabela são carregados na tabela de Upload e o processo segue normalmente, porém em alguns cenários não existe um processo externo para carregamento dessa tabela. para solucionar esse problema existe a opção "com query", quando habilitada essa opção abre um campo de texto para que possa ser inserida a query de insert na tabela de Staging, um caso de uso dessa funcionalidade é carga dos dados vindos de um Data Lake, essa prática é muito comum, quando utilizando o ambiente AWS, sendo assim a necessidade de uma ferramenta externa para carregar a tabela de Staging Area é mitigada.
Por padrão o 4insights realiza um TRUNCATE na tabela de Staging Area no final do processo, para limpar a tabela por completo, mas em alguns cenários durante o processo de carga são inseridos novos registros nessa tabela. e usando o TRUNCATE, haveria perca nos dados, para solucionar esse problema basta habilitar a opção "Habilitar Modo Transacional" que ao marcar essa opção no final do processo o 4insights realiza um DELETE pelas chaves da tabela, dessa forma somente os dados que entraram nessa carga serão apagados, e os dados novos serão mantidos para serem carregadas na próxima carga.
Obs.: Esse campo de query pode contém mais de uma query, e deve ser separada por ponto e virgula (;), lembrando que o objetivo desse campo e a carga na tabela de Staging Area.
8.1. Change Data Capture (CDC)
Quando utilizamos o tipo de entrada "Staging Area" com query, consideramos que existe uma fonte externas de informações, normalmente um Data Lake, mas nem sempre podemos carregar todos os dados, em ambientes produtivos a carga de tabelas com grandes volumes, como fatos por exemplo, devemos fazer um carregamento incremental e para isso o 4insights conta com uma funcionalidade que auxilia nesse processo, disponibilizando duas formas de controlar as alterações, ambas as formas necessita de uma interação com uma ferramenta externa, pois para incluir as informações de controle é necessário a chamada de API's REST, esses dois caminhos são:
CDC usando JSON:
Os dados de referência são incluidos via REST sendo passados em formato JSON, nesse formato o 4insights irá se encarregar de montar o cláusula Where de forma automática.
São necessários duas requisições para realizar a inclusão dos dados de controle. sendo eles a requisição de autenticação para obter o token de acesso e a requisição de inclusão do controle na API.
Requisição de Autenticação: Deve ser realizada uma requisição usando o método POST para a URL do exemplo abaixo (considerando o endereço do servidor) e informar no corpo da requisição o CLIENT_ID e CLIENT_SECRET que podem ser obtidos na criação de uma nova credencial.
POST /4insights-authentication/oauth/token HTTP/1.1
Host: (ENDEREÇO DO SERVIDOR)
Content-Type: application/x-www-form-urlencoded
grant_type=client_credentials&client_id=<CLIENT_ID>&client_secret=<CLIENT_SECRET>O resultado desta requisição é o Token de acesso que deve ser informado no cabeçalho Authorization da próxima requisição.
Requisição de inclusão dos dados de controle: Após obter o token de acesso, deve ser realizada uma requisição usando o método POST para a URL do exemplo abaixo (considerando o endereço so servidor) e informar no corpo da requisição o JSON informando as propriedades:
- customerName: Deve conter o nome do cliente cadastrado no 4insights.
- environmentName: Deve conter o nome do ambiente cadastrado no 4insights.
- moduleName: Deve conter o nome interno do módulo onde deve ser realizado o controle.
- type: Deve conter (APPEND ou OVERRIDE), esse valor se trata do tipo de alteração que está sendo inserida, APPEND para incluir o novo controle e OVERRIDE para substituir algum controle que já estiver cadastrado anteriormente.
- data: Deve conter o conteúdo em formato JSON do controle e considerar a seguinte regra: a propriedade deve conter o nome da coluna (e alias da tabela se existir) e o valor deve ser uma lista de texto ou um valor texto diretamente.
Exemplo da requisição:
POST /4insights/api/datamodeler/cdc/json HTTP/1.1
Host: (ENDEREÇO DO SERVIDOR)
Authorization: Bearer (TOKEN DE ACESSO)
Content-Type: application/json
{
"customerName": "NOME DO CLIENTE",
"environmentName": "NOME DO AMBIENTE",
"moduleName": "NOME DO MODULO",
"type": "APPEND",
"data": {
"<alias>.<column>": "<value>",
"<column>": ["<value1>", "<value2>"]
}
}
Para utilizar os dados de controle que foram adicionados podem ser utilizados nas áreas que podem receber SQL livre dentro do modelo de dados, tais como (SQL de Pré-Execução, SQL de Pós-Execução e Staging Area Query)
Para o 4insights considerar a utilização do controle deve ser adicionado o parâmetro ${cdc_sql} e no momento da execução da carga será substituído pelas informações adicionadas via API.

Você também pode incluir um valor padrão para caso o 4insights não consiga recuperar os dados de controle ou caso ele não os encontre.

Com esse exemplo caso não exista nenhum controle adicionado o valor da variavel será substituido por 1=1.
CDC usando texto livre:
Os dados de referência são incluidos via REST sendo passados em formato texto livre, nesse formato o 4insights irá se encarregar de substituir o parâmetro cdc_raw pelo valor no controle.
São necessários duas requisições para realizar a inclusão dos dados de controle. sendo eles a requisição de autenticação para obter o token de acesso e a requisição de inclusão do controle na API.
Requisição de Autenticação: Deve ser realizada uma requisição usando o método POST para a URL do exemplo abaixo (considerando o endereço do servidor) e informar no corpo da requisição o CLIENT_ID e CLIENT_SECRET que podem ser obtidos na criação de uma nova credencial.
POST /4insights-authentication/oauth/token HTTP/1.1
Host: (ENDEREÇO DO SERVIDOR)
Content-Type: application/x-www-form-urlencoded
grant_type=client_credentials&client_id=<CLIENT_ID>&client_secret=<CLIENT_SECRET>
O resultado desta requisição é o Token de acesso que deve ser informado no cabeçalho Authorization da próxima requisição.
Requisição de inclusão dos dados de controle: Após obter o token de acesso, deve ser realizada uma requisição usando o método POST para a URL do exemplo abaixo (considerando o endereço so servidor) e informar no corpo da requisição o JSON informando as propriedades:
- customerName: Deve conter o nome do cliente cadastrado no 4insights.
- environmentName: Deve conter o nome do ambiente cadastrado no 4insights.
- moduleName: Deve conter o nome interno do módulo onde deve ser realizado o controle.
- type: Deve conter (APPEND ou OVERRIDE), esse valor se trata do tipo de alteração que está sendo inserida, APPEND para incluir o novo controle e OVERRIDE para substituir algum controle que já estiver cadastrado anteriormente.
- data: Deve conter o conteúdo em formato texto do controle.
Exemplo da requisição:
POST /4insights/api/datamodeler/cdc/raw HTTP/1.1
Host: (ENDEREÇO DO SERVIDOR)
Authorization: Bearer (TOKEN DE ACESSO)
Content-Type: application/json
{
"customerName": "NOME DO CLIENTE",
"environmentName": "NOME DO AMBIENTE",
"moduleName": "NOME DO MODULO",
"type": "APPEND",
"data": "<value>"
}
Para utilizar os dados de controle que foram adicionados podem ser utilizados nas áreas que podem receber SQL livre dentro do modelo de dados, tais como (SQL de Pré-Execução, SQL de Pós-Execução e Staging Area Query)
Para o 4insights considerar a utilização do controle deve ser adicionado o parâmetro ${cdc_raw} e no momento da execução da carga será substituído pelas informações adicionadas via API.

Para mais detalhes sobre as API's do 4insights acesse o endereço http://(servidor)/4insights/swagger-ui.html ou https://4insights.net/4insights/swagger-ui.html

9. Atributos
Ao criar um elemento do tipo Upload você deve criar os atributos, para criar um atributo, basta clicar no botão "Novo Atributo".

Será exibido um formulário separado em seções "Informações Básicas", "Informações Avançadas", "Chaves" e quando a propriedade "Habilitar inserção automática de chaves estrangeiras quando houver rejeição" está ligada é exibida uma nova seção "Inserção automática de chaves estrangeiras quando houver rejeição":
Informações Básicas
Nesta seção são definidos os campos "Nome" que deve conter no nome de negócio do atributo e o o campo "Nome Interno" que deve contém o nome físico, ou seja o nome na qual será criada a coluna nesta tabela no banco de dados.

Informações Avançadas
Nesta seção são definidos os campos "Tipo de dados", "Comentário", "Nulo" e "Checagem de valores", no campo "Tipo de dados" você deve selecionar o tipo de dado para os dados do atributo, os tipos disponíveis são:
- String - uma cadeia de caracteres alfabetais e é usada para textos, ao selecionar esse tipo é exibido um novo campo chamado "Tamanho" para que seja definido o tamanho máximo de caracteres que poderão ser inseridos nessa coluna;
- Integer - em português é o conjunto de número inteiros , ou seja: são compostos por números naturais ou negativos {..., -2, -1, 0, 1, 2, ...}. Geralmente usados para caracterizar chaves das tabelas;
- Datatime - usado para campos de data e hora;
- Number - usado para campos numéricos que podem ser decimais. Para isso, basta definir a precisão. Pode variar entre -2147483648 a +2147483648, ao selecionar esse tipo é exibido dois novos campos, chamados "Tamanho" e "Precisão", onde o campo "Tamanho" define o tamanho máximo de números que poderão ser inseridos nessa coluna e o campo "Precisão" define quantos números vão ser considerados após o separador de decimal;
- Boolean - para campos que indicam verdadeiro ou falso, 0 ou 1;
- Date - usado para campos de data;
- BigNumber - campos numéricos como “Number” mas que variam entre -9223372036854775808 e +9223372036854775808, ao selecionar esse tipo é exibido dois novos campos, chamados "Tamanho" e "Precisão", onde o campo "Tamanho" define o tamanho máximo de números que poderão ser inseridos nessa coluna e o campo "Precisão" define quantos números vão ser considerados após o separador de decimal.
Após o preenchimento dos campos acima, deve ser definido se o campo será permitido Nulo, caso o campo permita Nulo deve se manter marcado a opção "Nulo", caso contrário, deve desmarca-lo.
Já a opção "Checagem de valores" deve ser utilizada quando surge a necessidade de validar um ou mais valores pré-definidos para a coluna, por exemplo, uma coluna de Sexo do Cliente só deve conter os valores "M" ou "F".

Chaves
Nesta seção são definidos as características de consistência da coluna, tais como "Chave de Descrição", "Chave Primária" e nós módulos de fato a "Chave de Atualização".- Chave de Descrição: tem como objetivo identificar a coluna que contém a descrição das informações para a dimensão, Ex: em uma dimensão de Cliente a chave de descrição seria o Nome do Cliente.
- Chave Primária: pode ser marcada em mais de uma coluna e irá definir que os registros nunca se repetem na mesma tabela com os mesmos valores e também não podem receber valor nulo.
- Chave de Atualização: esse campo só pode ser habilitado em módulos de Fato e tem como objetivo identificar ao 4insights por quais colunas será feito o reprocessamento de dados que já estejam carregados, Ex. no módulo de vendas a chave de atualização é Data e Loja, sendo assim quando for enviado para processamento uma data e loja que já existem no bando de dados (DW) o 4insights se encarregará de limpar os dados da tabela de fatos, agregados e fotografias com a mesma data e loja que estão sendo processados para que aconteça o reprocessamento desses dados.
Inserção automática de chaves estrangeiras quando houver rejeição
Quando é habilitada a propriedade no módulo de dimensão "Habilitar inserção automática de chaves estrangeiras quando houver rejeição" essa seção é exibida na criação ou na edição de um atributo, contando um campo que de acordo com o tipo de dado muda o comportamento. Ex.: se o tipo de dado da coluna for Data este campo só aceitará data, isso acontece para todos os tipos de dados descritos neste tópico, conforme a imagem abaixo:

9.1. Associar
A associação de atributos ou (chave estrangeira) serve para criar o relacionamentos entre as tabelas do seu modelo de dados. É importante lembrar que, ao associar um atributo de outra dimensão, o 4Insights passa a realizar automaticamente a checagem da consistência deste relacionamento. Tecnicamente chamamos isso de integridade referencial. Normalmente esta funcionalidade de integridade referencial é realizada automaticamente para os bancos de dados relacionais, porém para os bancos de dados colunares, esta funcionalidade não existe, e por este motivo o 4Insights inclui esta checagem no seu algorítimo de processamento.
O 4Insights habilita os atributos de uma Lookup criada em uma dimensão para ser associada em outra dimensão, ou seja, os atributos de uma dimensão podem ser utilizadas em Upload, tanto de dimensões como em fatos. É desta maneira que o 4Insights constrói os relacionamento das tabelas, associando no Upload os campos de outras dimensões.
A razão pela qual os relacionamentos são associados nos objetos Uploads é que as informações que são carregadas nos Data Warehouse são sempre de sistemas externos, portanto é nas entradas que os relacionamentos devem ser garantidos e, tecnicamente, para o 4Insights, os módulos Upload são as integrações de entradas.
Quando você cria um atributo associado, ele se torna uma chave estrangeira dentro do módulo que está sendo tratado. Em todos os objetos que ele for referenciado, ele passa a ser considerado com FK (Foreign Key - Chave Estrangeira).

Para criar esse relacionamento basta clicar no botão "Associar Atributos" que se encontra na página de criação ou edição de um elemento do tipo "Upload", ao clicar nesse botão será listado todos os módulos de dimensão e você deve navegar até o nível da Lookup, ao identificar a Lookup desejada clique no botão "Associar" e serão exibidos a chave primária da Lookup em formato de listagem, para cada atributo listado existem duas opções para associação "Criar um novo atributo" e "Usar atributo existente", se caso o atributo sugerido ainda não exista na sua Upload você deve utilizar a opção "Criar novo atributo", pois essa opção irá de fato criar um atributo neste elemento, mas se caso o atributo já tenha sido criado neste elemento você deve utilizar a opção "Usar atributo existente" dessa forma o 4insights irá entender que esse atributo faz parte da chave estrangeira tornando-o uma referência para a Lookup escolhida.

9.2. Importar Atributos - CSV
É uma possibilidade, para ajudar na produtividade da modelagem dos dados, a importação dos atributos vindo de um arquivo CSV, isso possibilita a facilidade de criação dos atributos das tabelas para uso no modelador de dados.

Na tela de criação ou edição de um elemento do tipo "Upload", para visualizar o menu de importação, basta clicar no botão "Importar" ao clicar no botão será exibida uma caixa de seleção onde a primeira opção é o "CSV" ao selecionar essa opção note que será exibido um botão com o nome de "Baixar Template" que ao clicar nele, será efetuado um download do arquivo ilustrando como deve ser preenchido os campos.
O Template deve ser preenchido com as seguintes considerações:
- NAME - definir o nome lógico do atributo.
- INTERNAL_NAME - definir o nome físico do atributo.
- COMMENT - inserir um comentário opcionalmente.
- DATATYPE - inserir o tipo de dado do atributo, tendo disponível os seguintes tipos:
- String - uma cadeia de caracteres alfabetais e é usada para textos, ao selecionar esse tipo é exibido um novo campo chamado "Tamanho" para que seja definido o tamanho máximo de caracteres que poderão ser inseridos nessa coluna;
- Integer - em português é o conjunto de número inteiros , ou seja: são compostos por números naturais ou negativos {..., -2, -1, 0, 1, 2, ...}. Geralmente usados para caracterizar chaves das tabelas;
- Datatime - usado para campos de data e hora;
- Number - usado para campos numéricos que podem ser decimais. Para isso, basta definir a precisão. Pode variar entre -2147483648 a +2147483648, ao selecionar esse tipo é exibido dois novos campos, chamados "Tamanho" e "Precisão", onde o campo "Tamanho" define o tamanho máximo de números que poderão ser inseridos nessa coluna e o campo "Precisão" define quantos números vão ser considerados após o separador de decimal;
- Boolean - para campos que indicam verdadeiro ou falso, 0 ou 1;
- Date - usado para campos de data;
- BigNumber - campos numéricos como “Number” mas que variam entre -9223372036854775808 e +9223372036854775808, ao selecionar esse tipo é exibido dois novos campos, chamados "Tamanho" e "Precisão", onde o campo "Tamanho" define o tamanho máximo de números que poderão ser inseridos nessa coluna e o campo "Precisão" define quantos números vão ser considerados após o separador de decimal.
- SIZE - caso o atributo precise de um limite de caracteres, especificar neste campo.
- PRECISION - somente se o tipo de dado permitir.
- NULLABLE - indicar se o campo pode ser nulo, inserindo valores true ou false ou 0 ou 1.
- CHECK_VALUES - se o campo for usado para checagem de valores, inserir valores true ou false ou 0 ou 1.
- PRIMARY_KEY - pode ser marcada em mais de uma coluna e irá definir que os registros nunca se repetem na mesma tabela com os mesmos valores e também não podem receber valor nulo, para configurar este campo insira valores true ou false ou 0 ou 1.
- DESCRIPTION_KEY - tem como objetivo identificar a coluna que contém a descrição da informações para a dimensão, Ex: em uma dimensão de Cliente a chave de descrição seria o Nome do Cliente. Caso este atributo seja um campo descritivo, inserir valores true ou false ou 0 ou 1.
- REFRESH_KEY - esse campo só pode ser habilitado em módulos de Fato e tem como objetivo identificar ao 4insights por quais colunas será feito o reprocessamento de dados que já estejam carregados, Ex. no módulo de vendas a chave de atualização é Data e Loja, sendo assim quando for enviado para processamento uma data e loja que já existem no bando de dados (DW) o 4insights se encarregará de limpar os dados da tabela de fatos, agregados e fotografias com a mesma data e loja que estão sendo processados para que aconteça o reprocessamento desses dados.
Os campos que devem ser preenchidos no arquivo CSV tem a mesma estrutura da criação de um atributo feito diretamente pela tela, note a semelhança de acordo com a imagem abaixo:

Depois de preencher o arquivo você deve marcar a opção "Contém cabeçalho", pois se foi utilizado o Template o mesmo contém cabeçalho, logo após marcar essa opção clique no botão "Selecionar um Arquivo" e será aberta a caixa de seleção de arquivos de acordo com os sistema operacional. selecione o arquivo que foi preenchido e clique no botão "Importar", o resultado será os atributos preenchidos no CSV sendo exibidos na tela como se tivessem sido criados diretamente pela tela.
9.3. Importar Atributos - Data Lake
É uma possibilidade, para ajudar na produtividade da modelagem dos dados a importação dos atributos vindo do catalogo do Data Lake, sendo possível com isso reaproveitar alguns ou todos os campos e minimizando a necessidade de redigitar as mesmas informações, neste tópico será exemplificado como realizar essa importação.
Na tela de criação de um elemento do tipo Upload ou em sua edição, na parte inferior da tela clique no botão "Importar" e escolhendo o formato "Data Lake Catalog".

Ao selecionar esse formato é exibido uma caixa de seleção chamada de "Ambientes", nesta caixa de seleção será listado todos os ambientes criados na tela do Data Lake do 4insights filtrados pelo cliente também selecionado neste modelo. e ao selecionar o ambiente desejado é exibido uma lista com as tabelas disponíveis, conforme a imagem abaixo:


Depois que as tabelas forem listadas, clique na desejada para seleciona-la, e clique no botão "Próxima Etapa" e será exibido uma listagem com os campos da tabela selecionada. por padrão todos os campos vem desmarcados e podem ser marcados clicando em qualquer lugar referente ao campo, devem ser marcados no minimo 1 campo, conforme a imagem abaixo:

Depois basta clicar no botão Importar e sua tabela estará pronta para uso no modelador de dados, o resultado ficará como na imagem abaixo:

9.4. Importar Atributos - AWS Glue Catalog
É uma possibilidade, para ajudar na produtividade da modelagem de dados a importação dos atributos originados do AWS Glue, sendo possível com isso reaproveitar alguns ou todos os campos da tabela e minimizando a necessidade de redigitar as mesmas informações, neste tópico será exemplificado como realizar essa importação.

Na tela de criação de um elemento do tipo Upload ou em sua edição, na parte inferior da tela clique no botão "Importar" e escolhendo o formato "AWS Glue Catalog", após selecionar essa opção será exibidos 3 novos campos "Access Key", "Secret Key" e "Region", esses campos são referentes há autenticação para utilização do serviço na AWS.
Leia mais sobre isso clicando aqui.
Após preencher essas informações clique no botão "Próxima Etapa", serão exibidos a listagem com os bancos de dados disponíveis no Glue selecione um deles que clique no botão "Próxima Etapa", serão exibidas todas as tabelas para o banco de dados selecionado, selecione uma tabela e clique no botão " Próxima Etapa", serão exibidos uma listagem com todos os campos para a tabela selecionada, por padrão todos os campos vem desmarcados e podem ser marcados clicando em qualquer lugar referente ao campo, devem ser marcados no minimo 1 campo.
10. Lookups da dimensão
Após a definição da tabela de Upload, é necessário criar as tabelas de Lookups, definir a chave primária e chave de descrição de cada Lookup.
Da mesma maneira, clique com o botão direito do mouse e adicione um novo elemento, selecione o tipo Lookup, dê um nome lógico, um físico e um comentário, o comentário ajuda a descrever o tipo de informação que será carregada na tabela, e logo após salve.
Para carregar os atributos na tabela de Lookup, arraste da tabela de Upload e solte na Lookup os campos que farão parte desta tabela. Também é necessário informar qual campo será a chave primária. Neste momento é obrigatório escolher um campo que será utilizado como o descritivo desta lookup. O campo descritivo é o campo que dá sentido ao valor da chave primária, ou seja, o valor que descreve as informações, neste exemplo, temos o código da empresa e o nome, o código é a chave primária e o nome é a descrição.

Modo transacional
Por padrão no processo de carga de uma Lookup é criada uma tabela temporária para realizar a atualização dos registros, o que torna o processo mais rápido, porém no período da carga a Lookup fica indisponível para consulta o que pode ser um problema em determinados cenários, para solucionar esse problema existe o modo transacional, que ao habilitar o 4insights abre uma transação no banco de dados e faz um DELETE dos dados com a mesma chave primária para que os novos dados sejam inseridos, porém esse processo pode deixar a carga mais lenta.
![]()
11. Definição de hierarquias
Definindo as hierarquias
Após a criação da tabela de Upload é o momento de serem criadas as hierarquias do modelo de dados. Veja exemplo abaixo em que todas as Lookups partem da tabela de Upload e seguem para as respectivas tabelas do modelo. Desta forma, o acesso das tabelas pode ser feito de modo simples e

Para definir uma hierarquia você deve possuir uma Lookup que será o nível mais detalhado da dimensão. Neste exemplo incluímos a Lookup de (Produto). Ela possuirá a mesma chave primária da tabela de Upload, pois é o nível mais detalhado da dimensão. Nela são incluídos todos os campos de códigos das Lookups anteriores, que serão chaves de relacionamento entre as demais Lookups do modelo.
Entretanto, para cada código também são criadas novas Lookups com chaves primárias e campos de descrição. Neste exemplo, temos a Lookup de agrupamentos, como "Categoria do Produto", "Setor do Produto", "Família", "Sub-Família", etc.
Ao criar um nível de agrupamento, incluímos as chaves códigos dos níveis menos seletivos em cada lookup. Isso garante a modelagem de forma híbrida, qual recomendamos. Maior qualidade na informação, performance e uma maneira mais simples relacionar tabelas pelas ferramentas visualização dados.
Esta maneira de modelar, não é obrigatória, podemos criar modelo Star Schema, criando somente uma única Lookup de cada dimensão ou simplesmente um modelo Snowflake, relacionando as tabelas de forma hierárquica e simples.
12. Dimensão de Tempo
O 4insights possui uma dimensão de tempo padrão, que contém as Lookups (data, semana, mês, bimestre, trimestre, semestre e ano) e essas Lookups são alimentadas da mesma forma das dimensões comuns, com os dados sendo carregados para a tabela de entrada (Upload), porém a diferença é que os dados são gerados de forma automática, mas para gerar esses dados de forma correta, o 4insights utiliza de um parâmetro nas colunas da tabela de Upload para identificar qual tipo de informação será gerada, com isso você pode apagar colunas ou modificar sua nomenclatura para atender aos padrões do seu projeto, sem perder a automatização que o 4insights disponibiliza. Para demonstrarmos essa parametrização basta clicar duas vezes (duplo clique) no módulo de tempo e será aberta a sua tabela de Upload e as Lookups.

O próximo passo é clicar com o botão direito do mouse na tabela de Upload e clicar em Editar Propriedades, será aberta a tela de edição da tabela de Upload e será possível visualizar todos os atributos padrão do módulo de tempo.
Agora clique no botão "Editar" de um dos campos, e será exibido a tela de edição do atributo, note que a única diferença dos outros atributos das outras dimensões é a seção "Informações de Tempo", essa sessão é específica do módulo de tempo, sendo ela responsável por definir qual o tipo da informação que será gerada.

Ao clicar na caixa de seleção "Tipo do Valor" será exibida uma listagem com todos os tipos de data disponíveis no 4insights, sendo assim possível alterar o nome da coluna, seu comentário, sem que afete a geração dos dados, essa geração é realizada quando o módulo é iniciado e os dados gerados são carregados para dentro da tabela de Upload, o restante do processo segue de forma normal.
13. Fato
O modulo de fato tem como função armazenar informações que devem ser medidas, por este motivo que as métricas devem ser armazenadas nestas tabelas e as tabelas de dimensão os atributos.
Uma característica comum é que as tabelas de fatos em 99% dos casos possuem alguma chave da dimensão de tempo (data, semana, mês...), pois como armazenamos campos que serão utilizados para medir (métricas), os mesmos normalmente fazem sentido no decorrer do tempo. Por exemplo: Fato de Vendas, temos uma métrica "Valor da Venda com Impostos", este valor está associado a um determinado dia, semana, mês...
O módulo de fato (ou tabela de fato) é onde os dados poderão finalmente ser analisados, pois estarão suficientemente organizados – devido as dimensões desenhadas anteriormente – para que relatórios sejam gerados.
Ao contrário do módulo de dimensão que apresenta todo um espectro de informações que dão sentido ao fato que ocorreu. É por este motivo que chamamos de tabelas de fatos as que podem ser medidas ou dimensões as que representa uma dimensão do fato, que muitas vezes não terão utilidade alguma na hora da análise, mas que têm utilidade para organizar os dados e realizarem as conexões e relações corretas.
O módulo de fato conta com os tipos de tabelas já encontrados no módulo de dimensão (upload) e mais as tabelas de fotografia e de agregado.
Criar um módulo de fato não é diferente de criar uma dimensão. Para criá-lo, basta clicar com o botão direito do mouse na área de trabalho do Modelador de Dados, clicar em adicionar um módulo, nomeá-lo e adicionar um comentário. Você também pode habilitar a execução de um script SQL antes e/ou depois da execução do módulo, conforme foi demonstrado no tópico "Propriedades".

Após criar o módulo ele pode ser acesso da mesma forma que a dimensão, dando um duplo clique sobre o módulo recém criado e será aberto a área para que possa ser criadas a sequencia de tabelas, os objetos a serem criados para a conclusão de um módulo de fatos pode ser representado pela imagem abaixo:

Obs.: Não são necessárias a criação de tabelas do tipo Agregado ou Fotografia para a finalização de um módulo de Fato, esses objetos devem ser utilizados conforme a necessidade.
Usando a mesma regra da dimensão é necessário criar um elemento do tipo "Upload", ele é criado através do clique com o botão direito do mouse "Adicionar Elemento" e deve ter a mesma definição já demonstrada no tópico "Tabela de Upload".
Após criar a tabela de Upload e definir suas chaves, você deve criar um elemento com o tipo "Tabela de Fato" esse elemento representa a tabela negocio propriamente dita, sendo nela realizada todo tipo de consulta, já que conta com os dados já tratados em sua forma final, caso deseje habilitar a limpeza de histórico, basta selecionar a opção "Habilitar limpeza de histórico" e definir a opção de limpeza em cada dia, meses ou anos. Esta opção poderá ser definida em cada tabela que será criada no módulo de fatos. Por exemplo: para o módulo de fato "Vendas" de um varejo, você pode ter uma tabela fatos de vendas no detalhe do ticket com histórico de 5 anos definido e uma agregado no detalhe de mês com um histórico de 10 anos, conforme imagem abaixo:

13.1. Agregado
As fatos agregadas são informações que estão consolidadas por uma determinada regra de hierarquia do negócio, e que são baseadas em outra fato já existente no modelo que está geralmente no menor nível da hierarquia:
O maior exemplo deste tipo é agregação pelo tempo, como uma tabela de vendas. Uma tabela que analisa vendas faz mais sentido em uma tabela de agregado, pois as vendas somadas ao longo do tempo contemplam o total de vendas em uma semana, um mês ou um ano. Ou seja, teríamos uma tabela de venda por dia, uma agregada com a consolidação da venda por mês (agregando todos os dias de cada mês) e uma agregada por ano (consolidando as vendas dos meses por ano). Sempre uma tabela sendo base para a próxima, conforme a imagem abaixo:

Importante que o critério de tempo não é a única regra de possível agregação. Pode-se fazer por exemplo, uma regra de agregação, junto com o tempo ou separadamente, por uma estrutura de hierarquia mercadológica de produto ("Categoria do Produto", "Setor do Produto", "Família", "Sub-Família", etc.). No 4Insights, para fazer a agregação só é preciso definir um critério de agregação baseado em uma hierarquia (a própria dimensão de tempo é uma hierarquia).
O 4Insights pode realizar consolidações pelas regras de soma, maior valor, menor valor, ou uma regra que possa ser aplicada juntamente com estes critérios. Ex: soma de (se valor de venda for nulo, venda igual a 0, senão venda).
Para criar uma tabela agregada é muito simples, basta clicar com o botão direito do mouse na área em branco e clicar na opção "Adicionar Elemento" e selecionar o tipo "Agregado", nela também é possível criar a configuração de limpeza de histórico, a configuração é feita da mesma forma a tabela de fatos. após preencher todas as informações salve e arraste as ligações para a tabela agregada, logo depois de arrastar todos os campos desejados, clique com o botão direito do mouse na tabela agregada e clique na opção "Editar propriedades", será exibida a tela de edição e é nesse momento que definimos qual será o atributo de transformação.
Neste exemplo teremos uma tabela de fatos de "Vendas" e iremos agregar por mês, sendo assim nosso atributo será o campo de Data da Venda.

Após abrir para edição a tabela de agregada, clique no botão "Editar" do atributo desejado, o atributo deve ser uma chave estrangeira para que seja possível realizar a transformação, após clicar no botão "Editar" será possível visualizar uma nova seção chamada de "Agrupamento" nela vão conter 3 opções "Lookup de Transformação", "Função de Agregação" e "Agrupar", neste momento iremos usar a primeira opção Lookup de Transformação e nela será exibida uma arvore contendo a estrutura da Lookup e nesse momento definimos por qual campo será feita a transformação, neste exemplo como estamos usando um campo de data que utiliza a dimensão de tempo padrão do 4insights podemos escolher qualquer dos campos da imagem abaixo.

Neste caso selecionamos o campo "COD_MES" que representa o código do mês (Ex.: Data da Venda 01/01/2018 o Código do mês será 012018) ao clicar no botão "Associar" é exibido ao lado da opção "Lookup de Transformação" a informação de qual atributo foi selecionado.

Dessa forma já temos a nossa transformação de Dia para Mês, clique em "Salvar" para continuar as configurações, agora devemos configuras os campos que são agrupados, como por exemplo o Valor da Venda, para realizar essa configuração encontre um dos campos que serão agregados, no nosso exemplo iremos usar o atributo chamado "Valor Vendas Com Impostos", clique no botão "Editar" do atributo escolhido e será exibida a mesma seção "Agrupamento" da configuração do atributo anterior, mas a diferença é para esse campo iremos utilizar a opção "Função de Agregação" que representa qual a estrategia de agregação que aquele atributo vai usar (Ex.: Soma, Média, Contagem, Minimo, Maximo), mas também é possível não utilizar nenhuma função de agregação padrão e escrever um trecho de SQL no campo "Expressão" para que incluir uma regra customizada.

Após configurar todos os atributos que devem ser agregados, salve as alterações do elemento e as alterações podem ser visualizar dessa forma:

Por que criar uma tabela Agregada?
Outro ponto importante das tabelas agregadas é o ganho de espaço e a performance nas análises.
Espaço: considere que temos uma tabela de fato de vendas de um varejo com uma rede de supermercados com 1.000 lojas, e são vendidos por hora 10 milhões de itens. Neste caso teríamos uma tabela de 240 milhões por dia com 7,2 bilhões de itens vendidos por mês, por ano 172,2 bilhões. Além disso, esta tabela possui todos os detalhes da venda (dimensões): "Data da Venda", "Produto Vendido", "Loja que Vendeu", "Ponto de Venda", "Número da Nota Fiscal", "Horário da Venda", "Cliente que comprou" e as métricas: "Valor da venda com impostos", "Valor dos impostos", "Custo da Venda". Utilizando um agregado, podemos reduzir o número de linhas da tabela, mantendo-se a visão somente por mês, por exemplo, com os cálculos consolidados já prontos.
Performance: apesar de ser possível realizar análises de drill down ou drill up pelas ferramentas de front-end, isto acaba exigindo maior esforço e tempo, porque a cada mudança de nível, é necessário uma nova consulta no banco de dados para gerar a informação necessária. Através de uma tabela já agregada pelo nível que interessa, o acesso a informação torna-se mais rápido já que a informação está pronta e não é necessária transformação. Importante citar que pela agregada seria possível somente fazer drill up (subir nível) pelo front-end.
Para as tabelas agregadas, deve-se definir uma chave de atualização (refresh key). Esta chave é a regra que determina como a informação na tabela agregada será atualizada dependendo do que for atualizado na tabela fato original. Ex: supondo uma tabela fato de vendas por dia, loja, produto, valor de venda, e sua agregada por mês, loja, produto e valor de venda, a chave de atualização pode ser o mês e a loja. A chave de atualização deve sempre ser um critério que garanta que a informação agregada seja exatamente a mesma que exista na tabela original. Cuidado também para não criar uma regra genérica demais (por exemplo somente mês). Isto pode impactar na performance dos cálculos.
13.2. Fotografia
Este tipo de fato, também chamado como posicional, possui
dados que não podem ser somados em diferentes datas e que devem ser analisados de
modo isolado. Isto é, a informação é relevante na data em que ela ocorreu, mas
que fica distorcida se agregada em relação ao tempo. A importância deste tipo
de fato é ter informações estáticas, para posterior comparação (e não
agregação) do seu comportamento com relação a outros dias.
O melhor exemplo para demostrar isso é uma tabela com informação de estoque por dia. Se o estoque do primeiro dia é somado com o estoque do segundo dia, o dado de quantidade de itens em estoque estará errado, pois a informação real de estoque para o segundo dia é somente o que está registrado especificamente neste dia. Assim, a fotografia é referente a dados que devem ser analisados baseados somente no tempo em que ocorreram. Assim, podemos observar por esta tabela de fato, quais dias estamos com pouco estoque ou com muito estoque, e associar a outras variáveis para identificar possíveis problemas na gestão do estoque.

Para criar uma tabela de fotografia é muito simples, basta clicar com o botão direito do mouse na área em branco e clicar na opção "Adicionar Elemento" e selecionar o tipo "Fotografia", nela também é possível criar a configuração de limpeza de histórico, a configuração é feita da mesma forma a tabela de fatos. após preencher todas as informações salve e arraste as ligações para a tabela de fotografia, logo depois de arrastar todos os campos desejados, clique com o botão direito do mouse na tabela agregada e clique na opção "Editar propriedades", será exibida a tela de edição e é nesse momento que definimos qual será o atributo de transformação.
Neste exemplo teremos uma tabela de fotografia de "Estoque" e iremos agregar por mês, sendo assim nosso atributo será o campo de Data do Processamento.

Após abrir para edição a tabela de fotografia, clique no botão "Editar" do atributo desejado, o atributo deve ser uma chave estrangeira para que seja possível realizar a transformação, após clicar no botão "Editar" será possível visualizar uma nova seção chamada de "Fotografia" e "Lookup de Fotografia" e nela será exibida uma arvore contendo a estrutura da Lookup e nesse momento definimos por qual campo será feita a transformação, neste exemplo como estamos usando um campo de data que utiliza a dimensão de tempo padrão do 4insights podemos escolher qualquer dos campos da imagem abaixo.

Neste caso selecionamos o campo "COD_MES" que representa o código do mês (Ex.: Data da Venda 01/01/2018 o Código do mês será 012018) ao clicar no botão "Associar" é exibido ao lado da opção "Lookup" na seção "Fotografia" a informação de qual atributo foi selecionado e deve ser escolhido na caixa de seleção uma das dois opções (Ultimo elemento no relacionamento, Primeiro elemento no relacionamento), essa opção representa qual será a regra para o processo de carga, neste exemplo estamos utilizando um campo de data para realizar uma fotografia uma tabela de estoque por mês então se selecionarmos a opção "Primeiro elemento no relacionamento" o registro para o mês correspondente seria o primeiro dia do mês, sendo assim informações o como estava o estoque no primeiro dia do mês, nesse caso iremos utilizar a opção "Ultimo elemento no relacionamento", pois para essa tabela queremos visualizar como estava o estoque no final do mês, após escolher a configuração ficará dessa forma:

Dessa forma já temos a nossa transformação de Dia para Mês, clique em "Salvar" para esse atributo e clique em "Salvar" novamente para o elemento as alterações podem ser visualizar dessa forma:

14. Importar e Exportar Módulos
Exportação
O modelador de dados possibilita a exportação do modelo de dados para dois formatos (JSON e PDF), sendo o JSON representando o modelo de dados puro, sendo assim é possível reaproveitar módulos ou estruturas inteiras, dessa forma possibilitamos um alto significativo na produtividade da modelagem dos dados e o PDF para fins de documentação, pois ao exportar neste formato é gerada todas as informações referente ao modelo de dados.
Para exportar basta selecionar os módulos desejados usando o (CTRL + Clique) ou pressionando (CTRL + A) caso queira selecionar todos de uma vez, após selecionar clique no botão "Exportar" que fica no menu do canto esquerdo.

Ao clicar no menu será exibida uma página para seja possível escolher o formato de exportação (JSON, PDF, DataStage e Talend), após selecionar o formato, clique em "Exportar" e o arquivo será baixado para seu computador.
Importar
Para importar módulos do 4insights somente são permitidos arquivos no formato JSON, que tenham sido exportados anteriormente, para importar basta clicar no menu no canta esquerdo "Importar".

Ao clicar no menu será exibida uma página solicitando que seja selecionado um arquivo, para escolher o arquivo clique no botão "Selecione um arquivo" e será exibida a janela de seleção de arquivos do sistema operacional, selecione o arquivo no formato JSON e clique no botão "Importar"

15. Verificando Pendências
Conforme o usuário realiza as alterações, cria novos módulos o 4insights realiza uma validação na modelagem para verificar se ficou faltando alguma configuração importante para o sucesso da carga dos seus dados, as validações funcionam como uma critica e são exibidas em um formato de listagem e enquanto o modelo tiver pendências não será possível a aprovação da sua versão do modelo. para visualizar as pendencias basta clicar no menu no canto esquerdo "Abrir lista de pendências".

Obs.: Caso não encontre esse botão, significa que seu modelo não tem nenhuma pendência.
Ao abrir esse menu será exibida uma página com duas abas "Erro" e "Avisos", sendo que os avisos não iram impedir a aprovação do modelo.

a imagem acima ilustra um aviso que informa que no módulo "DIM_EMPRESA" foi criada uma tabela de upload, mas nenhuma Lookup.

Caso seu modelo tenha erros de validação será exibido desta forma:

a imagem acima ilustra um erro que informa que no módulo "DIM_EMPRESA" tem um elemento do tipo "Upload" que não tem chave primária definida.
16. Aprovando as Alterações
Aprovar as Alterações consiste em tornar disponível para que outros usuários consigam visualizar suas alterações e iniciar o processo de carga, até então todas as alterações estavam sendo visualizadas somente pelo usuário que habilitou a edição, para aprovar basta clicar no menu no canto esquerdo "Aprovar as alterações".

Ao clicar no menu será exibida a página para inclusão para o comentário da sua aprovação, o preenchimento do mesmo é obrigatório e recomendamos que será explicativo de acordo com as mudanças da versão para se consiga ter um rastreamento das modificações posteriormente.

Depois de preencher o comentário clique no botão "Aprovar" e suas alterações estarão disponíveis para serem utilizadas por outros usuários.
17. Desfazendo as Alterações
Como toda a modelagem de dados do 4insights é feita dentro de uma versão, é muito comum o usuário querer desfazer tudo que foi feito na versão atual por inúmeros motivos para desfazer as alterações basta clicar no menu do canto esquerdo "Desfazer as alterações".

Após clicar no menu será exibida uma mensagem de confirmação, pois não será possível recuperar o que foi desfeito nessa ação, ao clicar no botão "Ok" suas alterações serão desfeitas e o modelo estará novamente disponível para que outros usuários editem.

18. Visualizar Histórico
O 4insights permite a visualização de todas as versões do modelo por ambiente, para acessar esse histórico basta clicar no menu do canto esquerdo "Visualizar Histórico".

Após clicar neste menu será exibida a listagem do histórico, sendo essa visualização em formato de lista e ordenados pela versão mais recente, nessa listagem o usuário poderá visualizar quando se iniciou a edição, quando terminou e quem fez a alteração e seu devido comentário.

19. Obter versão especifica
No 4insights o usuário não só pode visualizar a versões anteriores, como também obter uma versão especifica que pode ser utilizada somente para visualização mas também para gerar uma nova versão a partir da versão obtida, para acessar essa página basta clicar no menu no canto esquerdo "Obter versão especifica".

Ao clicar neste menu será exibida uma listagem com os versões na mesma configuração da visualização do histórico, contendo o nome do usuário que realizou a alteração, a data de edição, data de aprovação o numero da versão e o comentário, e um botão no final de cada versão e ao clicar nele é carregado na área de modelagem.

Depois que a modelagem na versão selecionada for exibida na tela para gerar uma nova versão a partir dela, basta clicar no botão "Habilitar Edição" demonstrado no tópico "Primeiros Passos".
20. Migração de Módulos
Com a definição de mais de um ambiente
(desenvolvimento, homologação / qualidade e produção) e com o controle que o
4Insights impede de fazer alteração no modelo direto em ambiente de produção
(maiores informações vide item "Configurando Ambientes"), deve-se utilizar
a funcionalidade de migração de modelo entre ambientes. Isto garante o
isolamento necessário para realizar as atividades de desenvolvimento e
homologação antes da implantação em produção.
O processo é simples no menu do canto esquerdo clique no botão "Migrar modelo entre ambientes".

Após clicar no menu será exibido uma página que é separada por uma sequencia de etapas, na primeira etapa escolhe-se qual o ambiente origem após selecionar o ambiente clique no botão "Próxima etapa".

Na segunda etapa escolha o ambiente destino (somente dentro da mesmo Cliente), após selecionar o ambiente clique no botão "Próxima etapa".
Agora na ultima etapa será exibido uma listagem com todas as versões aprovadas do ambiente de Origem clique na versão desejada e clique no botão "Finalizar migração".

O 4Insights irá identificar as diferenças entre as versões escolhidas dos modelos e implantar as diferenças no destino, a migração é feita de forma incremental. Depois é só aprovar no ambiente destino a nova versão do modelo.
Isto é um processo automático, rápido e transparente.

21. Geração de Diagramas
A geração de diagramas é uma funcionalidade que possibilita o usuário gerar um diagrama em formato PNG a partir de um módulo de Fato sendo gerado uma imagem contendo todo o MER (Modelo-Entidade-Relacionamento), auxiliando assim o entendimento da modelagem em seu contexto final. para gerar um diagrama basta selecionar um módulo de Fato e clicar com o botão direito do mouse e selecionar a opção "Gerar diagramas".

Ao clicar nesse menu será exibida uma página solicitando que aguarde a geração do diagrama, quando os diagramas forem gerados os arquivos serão baixados para o seu computador em formato PNG. e o resultado será semelhante a imagem abaixo:

22. Propriedades do Modelo
Neste tópico iremos detalhar o funcionamento e utilização do menu "Propriedades" que pode ser acessado na página de modelagem de dados.

Primeiramente o menu de Propriedades tem a finalidade de customizar a nomenclatura padrão do 4insights, como por exemplo o prefixos das tabelas criadas no modelo, por padrão elas são definidas da seguinte forma.
- Upload = IN_
- Reject = R_IN_
- Lookup = D_
- Tabela de Fatos = A_
- Agregadas = A_
- Fotografias = A_
- Staging Area = STG_
Mas neste menu você alterar esse padrão e para as tabelas finas (Lookup, Tabela de Fatos, Agregadas e Fotografias) o usuário pode deixar em branco, caso não queira nenhum prefixo.

Também é possível definir a configuração das colunas internas que o 4insights inclui nas tabelas, como por exemplo a coluna DAT_ATUALIZACAO que contém a data do processamento. Mas nesta página o usuário pode customizar todas as colunas internas, tais como o Prefixo da coluna de SK_ (Essa coluna é marcada quando o usuário habilita o versionamento de uma dimensão, ao habilitar o 4insights inclui essa coluna para incluir um sequencial para identificar o código da versão, que por sua vez é concatenado com o nome da Lookup, Ex. SK_CLIENTE), que também pode ser alterado para Sufixo (Ex. CLIENTE_SK). conforme imagem abaixo:

O restante das colunas podem ser alteradas na seção "Colunas Padrão", tais como a Data de Atualização, Coluna que contém o código da rejeição, colunas de controle de Inicio e Fim da vigência para as dimensões versionadas.

23. Hierarquia de Versões
Neste tópico iremos detalhar o funcionamento e utilização do menu "Hierarquia de Versões" que pode ser acessado na página de modelagem de dados.

O menu de hierarquia de versão tem o proposito de ilustrar a arvore de alterações entre os seus ambiente, como por exemplo quando é migrada uma nova versão de desenvolvimento para homologação e de homologação para Produção.

Essa página é meramente ilustrativa e é utilizada para visualização das alterações, não sendo possível acessar as versões diretamente por essa página.
24. Configurações Avançadas
É comum no mundo do BI trabalharmos com altos volumes de informação e para que se obtenha uma boa performance é necessário ajustar configurações como particionamento de tabelas, chaves de distribuição quando se trabalha em Cluster, tipo de compressão e etc. Pensando nisso o 4insights foi feito para auxiliar também nesta parte do processo, atualmente as configurações avançadas podem ser realizadas usando o Amazon Redshift e ambiente Hadoop como Hortonworks ou EMR (Elastic Map Reduce da Amazon), essas configurações podem ser facilmente acessadas através do clique com o botão direito nos elementos (Uplaod, Lookup, Tabela de Fatos, Agregadas e Fotografias).
24.1. Amazon Redshift
O Amazon Redshift é um data warehouse rápido e escalável que permite analisar todos os dados de data warehouses e data lakes com simplicidade e economia. O Redshift oferece performance dez vezes maior que qualquer outro data warehouse usando machine learning, execução massivamente paralela de consultas e armazenamento colunar em discos de alta performance. Você pode configurar e implantar um novo data warehouse em alguns minutos para executar consultas em petabytes de dados em um data warehouse do Redshift e em exabytes de dados em um data lake criado no Amazon S3. Você pode começar aos poucos, pagando apenas 0,25 USD por hora, e escalar até 250 USD por terabyte por ano, menos de um décimo do custo de outras soluções.
Leia mais sobre clicando aqui.
Ao abrir a página de configurações avançadas do Amazon Redshift o usuário pode iniciar sua configuração escolhendo o estilo de distribuição (Even, Key, All). para decidir da melhor o estilo consulte a documentação da aws aqui.
Na próxima seção é configurado a chave de ordenação que pode ser selecionada uma ou mais colunas, para mais detalhes sobre a chave de ordenação consulte a documentação da aws aqui.
Na próxima seção é configurado a chave de compressão para as colunas, selecionado o tipo de compressão para cada coluna, para decidir qual tipo de compressão usar consulte a documentação da aws aqui.

24.2. Hadoop
Para as configurações avançadas de ambientes parametrizados usando Hadoop são possíveis definir dois tipos de parâmetros, o formato de arquivos que o ambiente irá criar dentro do repositório de arquivos, os formatos disponíveis são "Parquet", "Orc" e "Arvo", e segundo parâmetro é a coluna para particionamento da tabela, essa parametrização é muito importante que configurado em tabelas com altos volumes, como por exemplo tabelas de fatos, recomendamos utilizar uma coluna do tipo data, principalmente em tabelas de fatos.
