Data Lake
| Site: | 4Insights |
| Curso: | 4Insights |
| Livro: | Data Lake |
| Impresso por: | Usuário visitante |
| Data: | Sunday, 14 Dec 2025, 14:37 |
1. Primeiros Passos no Data Lake
Acessando o Data Lake

O Data Lake é uma ferramente facilitadora para criação de estrutura de tabelas. É nela que você poderá realizar a criação de estruturas de todas tabelas do seu banco origem em formato JSON, CSV, DataStage (XML) e Talend (XML). Essa facilidade trará enorme economia no tempo de criação de estrutura das tabelas.
O 4Insights é uma solução de múltiplas empresas e múltiplos ambientes. Consulte o módulo de Criação de Empresa deste treinamento para obter detalhes sobre como cadastrar novas empresas. Também consulte o tópico Configurando Ambientes para configurar os diferentes ambientes (como desenvolvimento; homologação; QA e produção).
Com a empresa e o ambiente configurados, para inciar o desenvolvimento de estruturas de tabela deve-se selecionar a empresa e, em seguida, o ambiente. Agora o Data Lake está pronto para ser usado.
2. Criando uma Tabela
Pata criar uma tabela no Data Lake é muito simples. Basta clicar no botão "+" localizado no menu superior esquerdo, como exemplo na imagem abaixo:

O campo "Nome" é referente um nome lógico (1) e o "Nome Interno" é o nome físico (2). O campo "Comentário" é muito importante para a organização dos dados: descrever as tabelas e até os atributos, é importante para que toda a estrutura dos dados esteja organizada. Também podemos utilizar o campo de descrição para informar detalhes relevantes dos dados: sua origem, como se obtém, quais são suas regras e tudo o que precisa estar documentado. Podemos também adicionar Tags as nossas tabelas e/ou colunas, elas podem ser usadas para identificar as tabelas/colunas em uma pesquisa.
Adicionar Colunas
Para adicionar colunas na tabela seguimos o mesmo conceito de nomenclatura das tabelas, com os campos nome, nome interno, comentários e tags. Porém temos mais algumas informações como, Tipo de Dados: deve-se selecionar o tipo de dado que será utilizado na coluna, sendo os tipos disponíveis:
- String - uma cadeia de caracteres alfabetais e é usada para textos;
- Integer - em português é o conjunto de número inteiros , ou seja: são compostos por números naturais ou negativos {..., -2, -1, 0, 1, 2, ...}. Geralmente usados para caracterizar chaves das tabelas
- Datatime - usado para campos de data e hora;
- Number - usado para campos numéricos que podem ser decimais. Para isso, basta definir a precisão. Pode variar entre -2147483648 a +2147483648;
- Boolean - para campos que indicam verdadeiro ou falso, 0 ou 1
- Date - usado para campos de data;
- BigNumber - campos numéricos como “Number” mas que variam entre -9223372036854775808 e +9223372036854775808.
- BigInteger - é um tipo imutável que representa um integer arbitrariamente grande, cujo valor teoricamente não tem limite superior ou inferior.
No campo "Tamanho" podemos limitar o tamanho do dado que será inserido na coluna que está sendo criada. O campo precisão é usado somente para tipo de dados Number ou BigNumber, usado somente quando precisamos definir a quantidade de casas depois da vírgula, por exemplo, para precisão do valor "9999,99" definimos o valor 2. No campo "Nulo" temos apenas dois valores "Sim" ou "Não" para definir se essa coluna poderá ter valor nulo ou não. E por último temos uma caixa de seleção "Particionada" indicando se a coluna poderá ser particionada ou não.
Os tipos de colunas que poderão ser particionadas são: String, Integer, BigInteger, Date e DateTime.
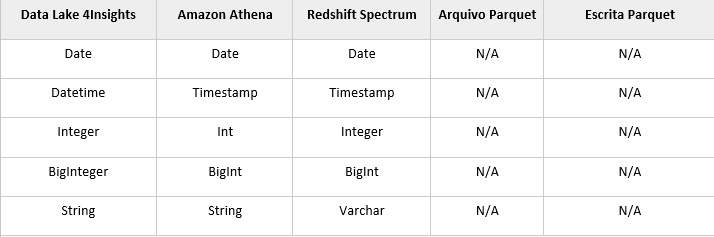
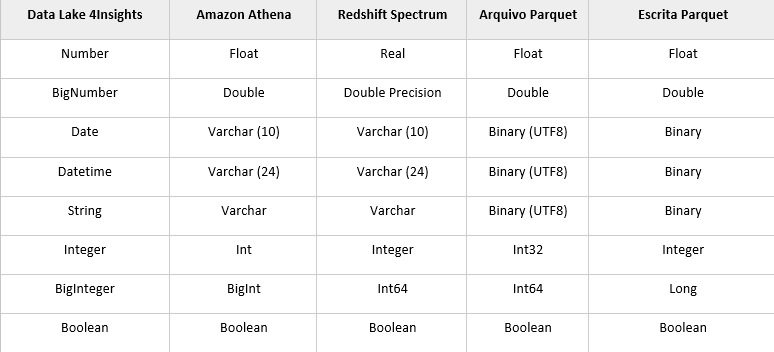
As tabelas a seguir representam como os tipos de dados serão tratados desde aplicação até a escrita dos arquivos em parquet para atributos particionados ou não particionados.
- Atributos Particionados
- Atributos Não Particionados
3. Importar ou Exportar
Importar
Para iniciar uma importação de tabelas para o data lake, é muito simples. Basta selecionar o botão "Importar" localizado no menu superior esquerdo, selecionar o formato de arquivo, dentre os formatos disponíveis temos JSON, CVS e AWS Glue.
- Para JSON - clique no botão "Selecione um arquivo" e navegue até o arquivo em um diretório local. Você pode utilizar a opção do 4Insights para exportar para gerar o arquivo no formato JSON. Ou seja, esta opção é utilizada quando se deseja exportar os metadados e importar novamente e serve como uma ferramenta para transportar as informações entre ambientes.
- Para CSV - marque a caixa "Contém Cabeçalho" se o arquivo tiver cabeçalho, e então clique no botão "Selecione um arquivo" e navegue até o arquivo em um diretório local.
Mapping Data Type
| COLUMN_DATATYPE | Target Data Type |
| 1 | String |
| 2 | Integer |
| 3 | Datetime |
| 4 | Number |
| 5 | Boolean |
| 7 | Date |
| 8 | BigNumber |
| 9 10 |
BigInteger Decimal |
Esta opção pode ser utilizada para importar um metadados de um banco de dados. Todo banco de dados possui um catálogo de informações das tabelas do banco de dados. Utilize a próxima seção para recuperar este catálogo com as query que extraem estas informações que poderão ser importadas e acelerar a importação destas informações sem a necessidade de digitação.

- Para AWS Glue - informe o access key, secret key e a região, marque a caixa "Substituir se existir" caso seja necessário e logo após em "Get Glue Databases", e então selecione os bancos, tabelas e colunas desejadas. Após ter finalizado a seleção, clique em "Importar Tabelas Selecionadas".

3.1. Extração metadados Oracle
É possível utilizar o Pentaho Data Integration para importar os metadados, criamos um plug-in que facilita esta ação. Desta forma basta criar uma conexão com o Banco de dados Oracle, selecionar as tabelas de metadados do Oracle e executar a transformação. Utilize o Link para baixar um exemplo desta transformação pronta.
Abaixo uma query de como extrair as informações do metadados do Oracle e a partir dela gerar um arquivo no formato formato CSV para para ser importada como explica a capítulo anterior.
SELECT trim(UPPER(COL.TABLE_NAME)) AS TABLE_INTERNALNAME,
trim(UPPER(COL.TABLE_NAME)) AS TABLE_NAME,
TAB_COMN.COMMENTS AS TABLE_COMMENT,
'' AS TABLE_TAGS,
trim(UPPER(COL.COLUMN_NAME)) AS COLUMN_INTERNALNAME,
trim(UPPER(COL.COLUMN_NAME)) AS COLUMN_NAME,
COL_COMN.COMMENTS AS COLUMN_COMMENT,
'' AS COLUMN_TAGS,
CASE WHEN DATA_TYPE IN ('VARCHAR2','CHAR','CLOB') THEN '1' --> String
WHEN DATA_TYPE IN ('NUMBER') AND DATA_SCALE = 0 AND DATA_PRECISION <= 9 then '2' --> Int (Number, Não possui casas decimais e é menor que oito pocisões)
WHEN DATA_TYPE IN ('NUMBER') AND DATA_SCALE = 0 then '9' --> Bigint (Number, Não possui casas decimais e é maior que oito pocisões)
WHEN DATA_TYPE IN ('NUMBER') AND (DATA_PRECISION-DATA_SCALE) <= 17 THEN '4' --Number
WHEN DATA_TYPE IN ('NUMBER') THEN '8' --BigNumber
WHEN DATA_TYPE IN ('DATE') THEN '3' --DateTime
WHEN DATA_TYPE IN ('TIMESTAMP(6)') THEN '3' --> Date Time
WHEN DATA_TYPE IN ('INTERVAL DAY(2) TO SECOND(6)') THEN '1' -- STRING
END AS COLUMN_DATATYPE, --> Data Type
CASE
WHEN DATA_TYPE IN ('VARCHAR2','CHAR','CLOB') THEN TO_CHAR(DATA_LENGTH)
WHEN DATA_TYPE IN ('NUMBER') AND DATA_SCALE = 0 THEN '0' --> Int ou Bigint (não é necessário especificar o tamanho do campo)
WHEN DATA_TYPE IN ('NUMBER') AND DATA_PRECISION IS NOT NULL THEN TO_CHAR(DATA_PRECISION)
WHEN DATA_TYPE IN ('NUMBER') AND DATA_PRECISION IS NULL THEN TO_CHAR(DATA_LENGTH)
WHEN DATA_TYPE IN ('DATE') THEN TO_CHAR(DATA_LENGTH)
WHEN DATA_TYPE IN ('TIMESTAMP(6)') THEN ''
WHEN DATA_TYPE IN ('INTERVAL DAY(2) TO SECOND(6)') THEN '20' -- STRING 20
END AS COLUMN_SIZE, --> Tamanho do campo
CASE WHEN DATA_TYPE IN ('NUMBER') AND DATA_SCALE IS NOT NULL THEN TO_CHAR(DATA_SCALE)
WHEN DATA_TYPE IN ('NUMBER') AND DATA_SCALE IS NULL THEN '0'
ELSE '0'
END AS COLUMN_PRECISION, --> Casas decimais
CASE NULLABLE
WHEN 'N' THEN '0'
WHEN 'Y' THEN '1'
END AS COLUMN_NULLABLE,
'0' COLUMN_PARTITIONED
FROM ALL_TAB_COLUMNS COL
LEFT JOIN all_TAB_comments TAB_COMN ON (COL.OWNER = TAB_COMN.OWNER AND COL.TABLE_NAME = TAB_COMN.TABLE_NAME)
LEFT join all_COL_comments COL_COMN ON (COL.OWNER = COL_COMN.OWNER AND COL.TABLE_NAME = COL_COMN.TABLE_NAME AND COL.COLUMN_NAME = COL_COMN.COLUMN_NAME)
WHERE COL.TABLE_NAME in ('TABLE 1','TABLE 2') --> Substitua aqui a lista das tabelas a serem importadas
and col.owner in ('OWNER 1','OWNER 2') --> Substitua aqui a lista de Owners a serem importados
order by UPPER(COL.TABLE_NAME), COL.COLUMN_ID
3.2. Extração metadados SQL-Server
É possível utilizar o Pentaho Data Integration para importar os metadados, criamos um plug-in que facilita esta ação. Desta forma basta criar uma conexão com o Banco de dados SQL-Server, selecionar as tabelas de metadados do SQL-Server e executar a transformação. Utilize o Link para baixar um exemplo desta transformação pronta.
Abaixo uma query de como extrair as informações do metadados do SQL-Server e a partir dela gerar um arquivo no formato formato CSV para para ser importada como explica a capítulo anterior.
select UPPER(COLUMNS.TABLE_NAME) AS TABLE_INTERNALNAME,
UPPER(COLUMNS.TABLE_NAME) AS TABLE_NAME,
'' AS TABLE_COMMENT,
'' AS TABLE_TAGS,
UPPER(COLUMN_NAME) AS COLUMN_INTERNALNAME,
UPPER(COLUMN_NAME) AS COLUMN_NAME,
CONVERT(VARCHAR,P.value) AS COLUMN_COMMENT,
'' AS COLUMN_TAGS,
CASE
DATA_TYPE
WHEN 'bigint' THEN 9
WHEN 'float' THEN 8
WHEN 'bit' THEN 1
WHEN 'char' THEN 1
WHEN 'date' THEN 7
WHEN 'datetime' THEN 3
WHEN 'datetime2' THEN 3
WHEN 'decimal' THEN 4
WHEN 'money' THEN 4
WHEN 'numeric' THEN 4
WHEN 'int' THEN 2
WHEN 'nchar' THEN 1
WHEN 'NTEXT' THEN 1
WHEN 'text' THEN 1
WHEN 'nvarchar' THEN 1
WHEN 'smalldatetime' THEN 3
WHEN 'smallint' THEN 2
WHEN 'tinyint' THEN 2
WHEN 'uniqueidentifier' THEN 1
WHEN 'varbinary' THEN 1
WHEN 'varchar' THEN 1
WHEN 'boolean' THEN 1
WHEN 'timestamp' THEN 1 END AS COLUMN_DATATYPE,
CASE
WHEN DATA_TYPE = 'nvarchar' THEN coalesce(character_maximum_length,4000)
WHEN DATA_TYPE = 'varchar' and CHARACTER_MAXIMUM_LENGTH = '-1' THEN 4000
WHEN DATA_TYPE = 'NTEXT' THEN 65535
WHEN DATA_TYPE = 'uniqueidentifier' THEN 36
WHEN DATA_TYPE = 'timestamp' THEN 36
WHEN DATA_TYPE = 'boolean' THEN 1
WHEN DATA_TYPE = 'bit' THEN 1
WHEN DATA_TYPE = 'varbinary' THEN coalesce(character_maximum_length,4000)
WHEN DATA_TYPE = 'decimal' THEN CONVERT(VARCHAR,NUMERIC_PRECISION)
WHEN DATA_TYPE = 'bigint' THEN CONVERT(VARCHAR,NUMERIC_PRECISION)
WHEN DATA_TYPE = 'int' THEN CONVERT(VARCHAR,NUMERIC_PRECISION)
WHEN DATA_TYPE = 'smallint' THEN CONVERT(VARCHAR,NUMERIC_PRECISION)
WHEN DATA_TYPE = 'tinyint' THEN CONVERT(VARCHAR,NUMERIC_PRECISION)
WHEN DATA_TYPE = 'money' THEN CONVERT(VARCHAR,NUMERIC_PRECISION)
WHEN DATA_TYPE = 'numeric' THEN CONVERT(VARCHAR,NUMERIC_PRECISION)
WHEN CHARACTER_MAXIMUM_LENGTH IS NULL THEN ''
ELSE CHARACTER_MAXIMUM_LENGTH END AS COLUMN_SIZE,
CASE
WHEN NUMERIC_SCALE IS NULL THEN ''
WHEN DATA_TYPE = 'decimal' THEN CONVERT(VARCHAR,NUMERIC_SCALE)
WHEN DATA_TYPE = 'bigint' THEN CONVERT(VARCHAR,NUMERIC_SCALE)
WHEN DATA_TYPE = 'int' THEN CONVERT(VARCHAR,NUMERIC_SCALE)
WHEN DATA_TYPE = 'tinyint' THEN CONVERT(VARCHAR,NUMERIC_SCALE)
WHEN DATA_TYPE = 'smallint' THEN CONVERT(VARCHAR,NUMERIC_SCALE)
WHEN DATA_TYPE = 'money' THEN CONVERT(VARCHAR,NUMERIC_SCALE)
WHEN DATA_TYPE = 'numeric' THEN CONVERT(VARCHAR,NUMERIC_SCALE)
ELSE '' END AS COLUMN_PRECISION,
CASE
IS_NULLABLE WHEN 'NO' THEN 0
WHEN 'YES' THEN 1 END AS COLUMN_NULLABLE,
'0' AS COLUMN_PARTITIONED
FROM INFORMATION_SCHEMA.COLUMNS
LEFT JOIN sys.extended_properties p
ON (p.major_id = OBJECT_ID(COLUMNS.TABLE_NAME) AND p.minor_id = COLUMNPROPERTY(p.major_id, COLUMNS.COLUMN_NAME, 'ColumnID') and p.name = 'MS_Description')
WHERE COLUMNS.TABLE_CATALOG = 'CATALOGO 1' -- substitua aqui o nome do catalogo a ser extraido
AND TABLE_NAME in ('TABLE 1', 'TABLE 2') -- substitua aqui a lista das tabelas para recuperar o catalogo
Order by COLUMNS.TABLE_NAME,ORDINAL_POSITION
3.3. Extração metadados Informix
select TABLE_INTERNALNAME,
TABLE_NAME,
TABLE_COMMENT,
TABLE_TAGS,
COLUMN_INTERNALNAME,
COLUMN_NAME,
COLUMN_COMMENT,
COLUMN_TAGS,
COLUMN_DATATYPE_ID,
CASE WHEN COLUMN_DATATYPE_ID = 4 THEN TRUNC(COLUMN_LENGTH/256)
WHEN COLUMN_DATATYPE_ID = 1 THEN COLUMN_LENGTH
ELSE 0 END AS COLUMN_LENGTH,
CASE WHEN COLUMN_DATATYPE_ID = 4 AND MOD(COLUMN_LENGTH,256) <> 255 THEN MOD(COLUMN_LENGTH,256)
ELSE 0 END AS COLUMN_PRECISION,
COLUMN_NULLABLE
from (select 'IFX_0000_SIS_V1_' || UPPER(tabname) AS TABLE_INTERNALNAME
,'IFX_0000_SIS_V1_' || UPPER(tabname) AS TABLE_NAME
,'' AS TABLE_COMMENT
,'' AS TABLE_TAGS
,colname as COLUMN_INTERNALNAME
,colname as COLUMN_NAME
,'' as COLUMN_COMMENT
,'' AS COLUMN_TAGS
,CASE WHEN MOD(coltype,256)=0 THEN 1
WHEN MOD(coltype,256)=1 THEN 2
WHEN MOD(coltype,256)=2 THEN 2
WHEN MOD(coltype,256)=3 THEN 4
WHEN MOD(coltype,256)=4 THEN 4
WHEN MOD(coltype,256)=5 THEN 4
WHEN MOD(coltype,256)=6 THEN 2
WHEN MOD(coltype,256)=7 THEN 7
WHEN MOD(coltype,256)=8 THEN 4
WHEN MOD(coltype,256)=10 THEN 3
WHEN MOD(coltype,256)=11 THEN 2
WHEN MOD(coltype,256)=12 THEN 1
WHEN MOD(coltype,256)=13 THEN 1
WHEN MOD(coltype,256)=14 THEN 1
WHEN MOD(coltype,256)=15 THEN 1
WHEN MOD(coltype,256)=16 THEN 1
WHEN MOD(coltype,256)=17 THEN 2
WHEN MOD(coltype,256)=40 THEN 1
WHEN MOD(coltype,256)=41 THEN 5
WHEN MOD(coltype,256)=45 THEN 5
WHEN MOD(coltype,256)=52 THEN 9
WHEN MOD(coltype,256)=53 THEN 1
END AS COLUMN_DATATYPE_ID
,collength AS COLUMN_LENGTH
,CASE WHEN coltype >= 256 THEN 0
ELSE 1 END AS COLUMN_NULLABLE
from informix.syscolumns as c join informix.systables as t on t.tabid = c.tabid
WHERE t.tabname in ('nf_etiq_emitidas'));
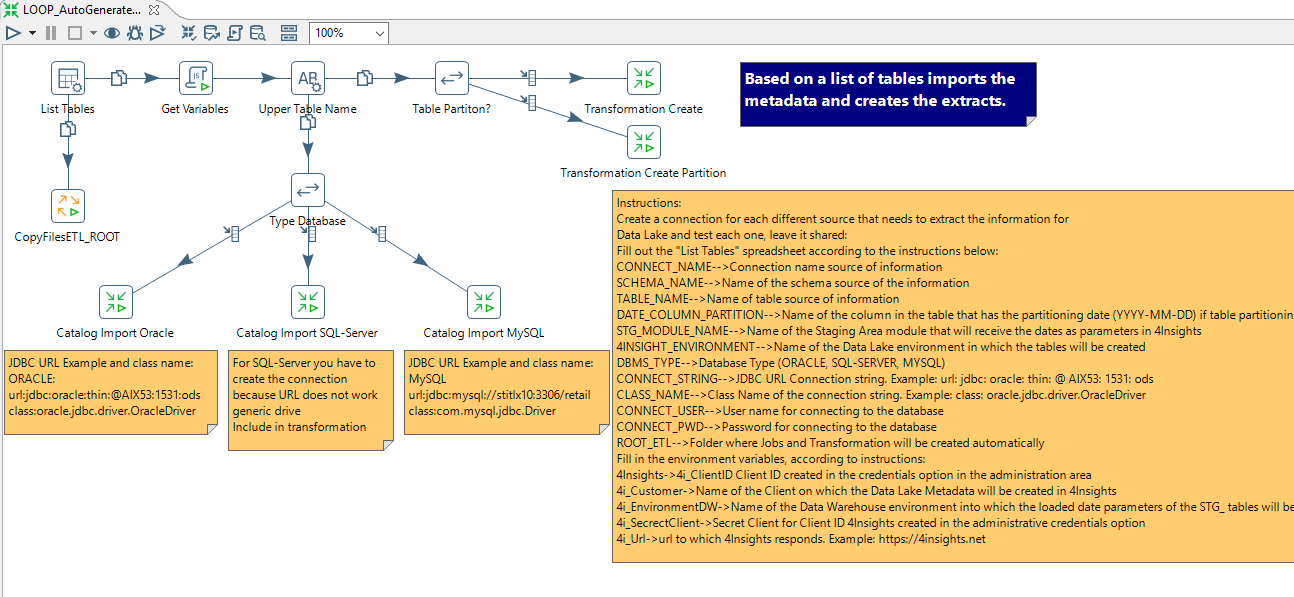
4. PDI - Geração automática Data Lake - PDI
Aqui você pode baixar um Job que é capaz de importar os metadados das tabelas dos bancos de dados para dentro do 4Insights e criar Jobs e transformações na ferramenta PDI (Pentaho Data Integration) para construir automaticamente o Data Lake. Estes Jobs convertem os dados das tabelas para um formato de Big Data e levam as informações para o S3 da AWS e criam o catálogo no Glue, deixando as informações disponíveis para serem consultadas pelo Athena.
Para baixar os Jobs e transformações, click aqui. Descompacte o arquivo etl.zip em algum local do servidor (Compatível com Linux e Windows/32 ou 64 Bits).
Abra a transformação "LOOP_AutoGenerateTransformation.ktr" no PDI, complete a "List Tables" com as instruções existentes na própria transformação, com os parâmetros necessários, edite os parâmetros e crie as conexões, bem como baixe os Drivers de banco de dados necessários.
Após a geração dos Jobs e Transformações, é necessário abrir cada uma das transformações geradas e no componente do 4Insights (4I) ir na aba "Fileds" e clicar no botão "GetFields", para recuperar os atributos das tabelas, tipos de dados e formatações que o 4Insights deverá gerar o Data Lake para cada tabela.
Para as tabelas Particionadas, o 4Insights cria automaticamente o controle de envio das datas das partições da última execução. Você pode utilizar a variável CDC_SQL, veja tópico para maiores esclarecimentos.
As transformações que possuem transformação é necessário informar quais as datas devem ser carregadas. Por exemplo último 7 dias. Abra o primeiro componente da transformação e altere a data por alguma lógica que faça sentido.
Dicas:
1)Particione tabelas que possuem movimentos de dados e o histórico é grande.
2)Coloque um atributo de data sem hora, minuto e segundos;
3)Depois que o Metadados é importado para o catálogo do 4Insights é necessário abrir o catalogo e informar as colunas que devem ser particionadas das tabelas, pois o 4Insights não importa as colunas das tabelas particionadas.